
MiniCPM-V是由OpenBMB开发的一款面向端侧部署的多模态大型语言模型(MLLM),支持图像、视频和文本输入,提供高质量的文本输出。
详细介绍:
主要功能:
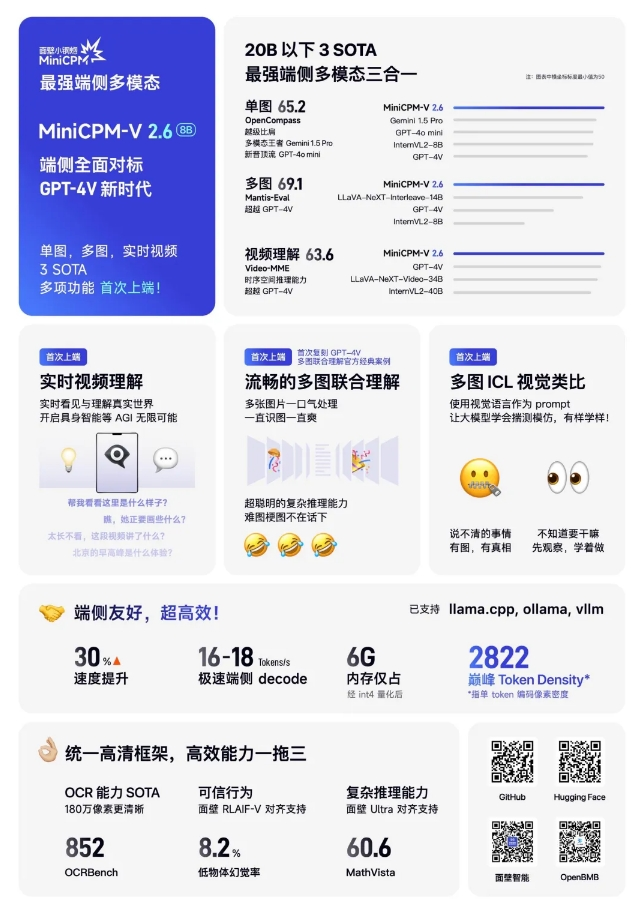
MiniCPM-V系列模型专为视觉-语言理解设计,能够处理包括单图像、多图像和视频理解在内的多种任务。
模型具有强大的OCR能力、低幻觉率、多语言支持,并特别优化了端侧部署的效率。
使用方法:
通过GitHub仓库提供的安装指南和代码示例,用户可以在多种设备上部署和运行MiniCPM-V模型。
支持使用Hugging Face的Gradio来快速搭建本地WebUI演示或在线演示。
适用场景:
适用于需要在移动设备或个人电脑上进行图像和视频内容理解的场景。
适用于多语言环境下的多模态交互和内容生成。
适用人群:
研究人员和开发者,特别是在多模态学习和人工智能领域。
需要在产品中集成图像和视频理解能力的企业和应用开发者。
优缺点介绍:
优点:
模型轻量化,便于在资源受限的设备上部署。
支持多语言和高分辨率图像,具有强大的视觉-语言理解能力。
开源,社区活跃,易于获取支持和进行二次开发。
缺点:
作为新模型,可能在特定任务上的表现尚未经过广泛验证。
对于没有技术背景的用户,部署和使用可能存在一定门槛。
分类标签推荐:
多模态学习、视觉-语言模型、端侧部署、人工智能、机器学习
MNN TaoAvatar是阿里巴巴基于其开源的轻量级深度学习推理框架MNN开发的3D数字人技术,支持真3D虚拟角色的实时生成与驱动,能够在手机等移动设备上以高达90FPS的帧率运行,带来流畅的交互体验。