2025 年 8 月 11 日,昆仑万维科技股份有限公司正式发布 SkyReels-A3 模型,这是一款基于 “DiT(Diffusion Transformer)视频扩散模型 + 插帧模型进行视频延展 + 基于强化学习的动作优化 + 运镜可控” 的音频驱动数字人创作工具。该模型的发布,标志着 AI 视频生成技术迈入了新的发展阶段,为内容创作带来了更多可能性。
一、技术特点
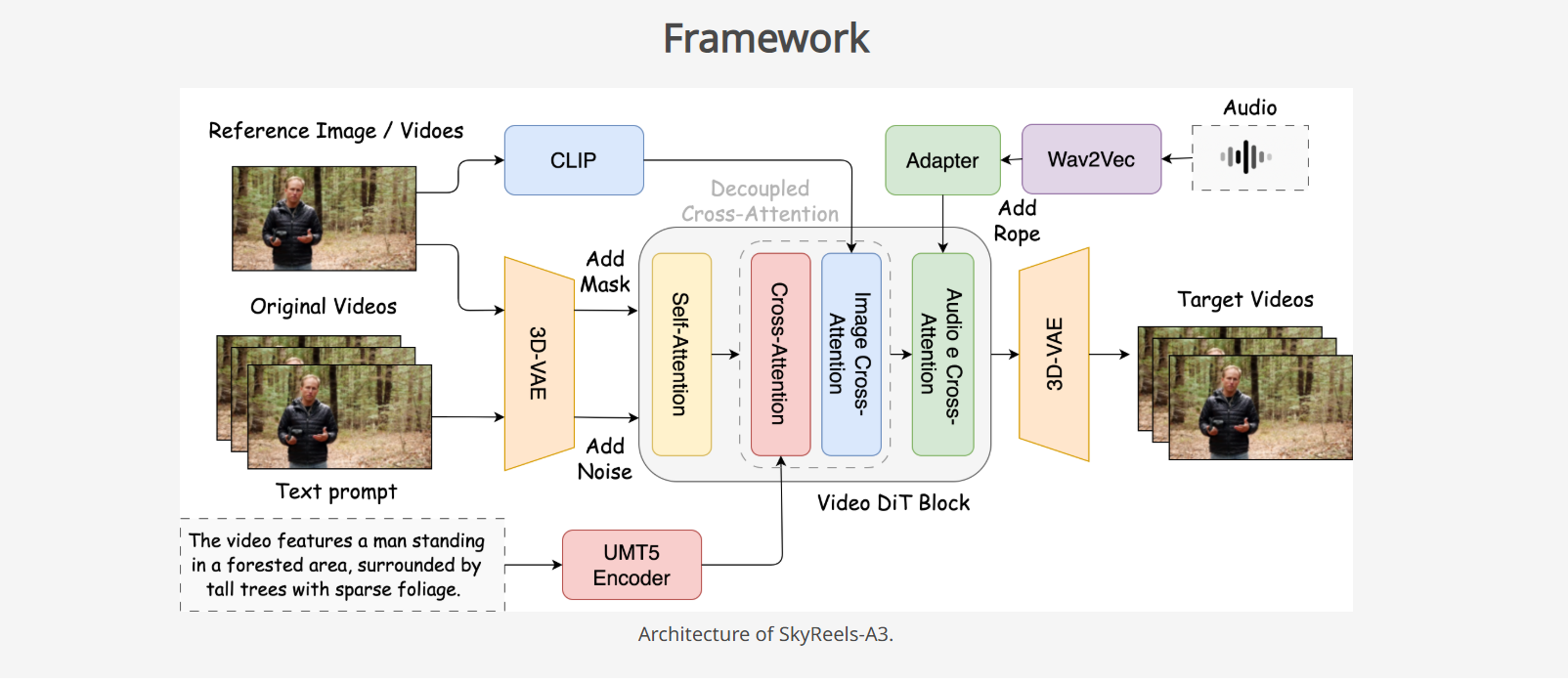
SkyReels-A3 模型具有多项创新技术特点。其基于 DiT 架构,通过优化视频生成效率和质量,实现了多模态融合,能够结合音频、视觉和动作控制,进行跨模态的协同生成。此外,该模型还引入了基于 ControlNet 结构的镜头控制模块,通过精细化镜头参数的输入,实现帧级别精准运镜控制。在定量评估中,SkyReels-A3 在唇形同步等指标上超越了 OmniHuman 等同类模型,并且通过技术优化将生成步数从 40 步减至 4 步,大幅提升了效率。
二、应用场景
SkyReels-A3 模型的应用场景十分广泛。它可以实现让一张照片 “活” 起来,上传人像图片和语音,照片中的人物就能开口说话或唱歌;也可以创作一段新的视频,用户只需提供人像图片、语音和文字提示,即可生成按照要求状态进行表演的视频;还能为现有视频 “改台词”,自动匹配新的口型、表情和表演,保持画面连贯。此外,该模型还针对线上直播等实际应用场景进行了特定优化,提高了视频生成的一致性和特定交互动作的自然度和清晰度。在艺术创作方面,其首创的镜头控制模块支持多种运镜参数,且强度可自由连续调节,能够显著提升音乐 MV、电影片段等艺术场景的表现力。
三、行业意义
SkyReels-A3 模型的推出,为广告、直播带货等商业应用提供了强有力的技术支持,也为音乐 MV、电影片段或演讲视频等艺术创作提供了更多可能性。它不仅能够提升内容创作的效率和质量,还能降低创作成本,使更多创作者能够轻松地制作出高质量的数字人视频内容。此外,该模型的发布也标志着昆仑万维 AI 技术全面迈入商业化应用阶段,其前期重投入的研发成果加速转化为产品矩阵,技术变现飞轮高效运转。
四、未来展望
随着 AI 技术的持续演进,SkyReels-A3 有望进一步扩展应用场景,例如结合语音、手势、情感识别等多模态输入,提升交互体验;支持移动端、VR/AR 等多终端应用;推动技术开源,降低行业门槛,促进 AI 内容创作的普惠化。