网易有道近日正式发布子曰4.0大模型,标志着这一系列模型全面迈入"全模态"时代。子曰4.0不仅实现了文本、图像、音频的高效融合与交互,还采用完全开源的方式,将核心技术资产贡献给开发者社区,旨在通过开源生态降低AI应用的成本与门槛。
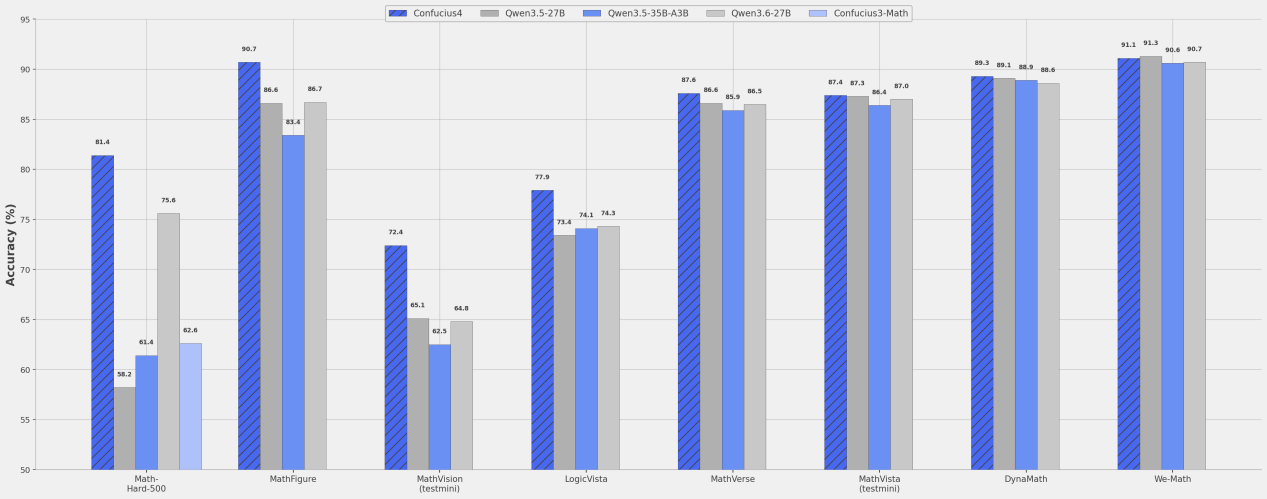
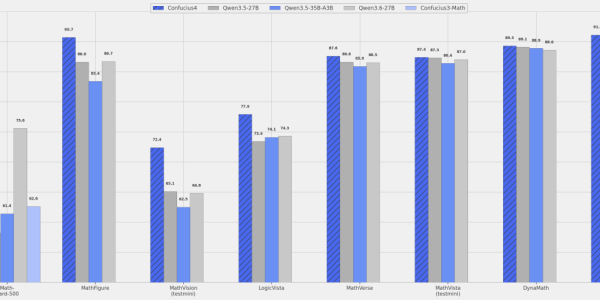
子曰4.0的核心性能提升主要集中在以下三个维度:多模态融合交互方面,模型实现了文本、视觉、听觉信息的统一表示与处理,支持多模态类型的自然切换;27B数学逻辑SOTA方面,81.4%的中文纯文本数学问题准确率达到同规模行业最佳水平;重构翻译引擎方面,推理速度提升80%,在保持高效推理的同时实现翻译质量的质的飞跃。
一、核心技术突破:推理链压缩43.2%,成本效益翻倍
子曰4.0多模态模型采用精选推理链重构方案(Refined CoT),通过聚合大量高质量、简洁的推理样本进行深度优化,成功将推理链输出长度压缩43.2%。这意味着在相同的算力消耗下,模型能够提供更快的响应速度、更少的Token消耗,显著降低企业实际业务场景中的推理成本。
在视觉数学能力上,27B参数规模已在教育场景的视觉输入数学能力上达到行业最佳(SOTA),在处理图表类高级数学物理问题时表现尤为突出。此外,子曰4.0研究团队针对中国学生真实作业、考试、题目场景进行了深度优化,能够真正解决中国学生面临的学习难题。
二、开源TTS引擎:3秒克隆声音,14语言无口音
随多模态模型一同开源的还有语音合成(TTS)引擎。该引擎基于前沿"语音编码器+LLM"架构构建,为开发者和内容创作者提供零样本、低门槛的语音克隆与情感合成能力。
当前系统支持中文、英文、日语、韩语、德语、法语、西班牙语、印度尼西亚语、意大利语、泰语、葡萄牙语、俄语、马来语、越南语共14种语言,且跨语言克隆时能自然保持说话人的音色,不会出现口音泄露问题。
在语音克隆方面,用户只需提供任意音频材料,系统即可在3秒内完成原始声音复刻。据官方介绍,该引擎克隆任务准确率超过97%,克隆声音与原声相似度超过85%,在保持说话人独特声音特征的同时,能准确再现情感语调。
三、全模态生态战略:开源+教育,扩展无限可能
网易有道的全面开源被视为国内大模型竞争的重要转折点。通过将"语音+视觉+逻辑推理"的底层能力释放给开发者,有道正试图将自身技术影响力从单一的教育应用领域扩展到更广泛的通用场景。
开源的CoT(思维链)内部逻辑重构,使开发者在推理阶段获得更低��计算资源消耗,为开发者提供了一个兼顾"性能"与"应用成本"的开源解决方案。随着开源社区的不断壮大,子曰4.0有望成为教育科技、创意内容、语言服务等多个领域的重要基础设施。
子曰4.0的发布不仅是有道自身技术实力的集中展现,更代表了一种"开源普惠"的生态战略。通过降低AI应用的技术门槛,让更多开发者、企业乃至个人能够参与到AI创新浪潮中。可以预见,随着开源社区的持续贡献,子曰4.0的能力边界还将不断拓展。